新型コロナの感染状況(2020/4/11)
前回の記事で、OpenJUMPを使って新型コロナの感染状況などを地図にグラフ表示しました。
今回は、WHOからの感染データをPythonで自動的に取得し、先週分との比較グラフを表示します。
PythonでWHOデータをスクレイピング
前回紹介しましたが、WHO(世界保健機関)の新型コロナ情報公開サイトには、国別の感染者数や検査数などが公開されています。
前回は、このサイトから手作業でテキストエディタにコピペして編集後、OpenJUMPへ取り込みました。
今週もこの方法でもよかったのですが、以前から気になっていたPythonの”Beautiful Soup”パッケージを使って自動化を試みました。いわゆる”ウェブスクレイピング”(以降、単にスクレイピング)です。
スクレイピングとは、Web上の各種コンテンツから意図したデータを抽出するような行為を意味しています。著作権などを考えると結構微妙な行為だと思っていますが、今回のような世界的な課題に対する情報公開のためのスクレイピングは、情報の公開者であるWHOの趣旨にも合致すると考え、作業に着手しました。
まずはテーブルデータの確認
スクレイピングにあたってホームページ上のデータを確認します。
サイト上では、各国のデータが以下のような表となっています。

この表は、以下のようなHTMLで表現されています。
<table id="main_table_countries_today" class="table table-bordered table-hover main_table_countries" style="width:100%;margin-top: 0px !important;">
<thead>
<tr>
<th>#</th>
<th width="100">Country,<br />Other</th>
<th width="20">Total<br />Cases</th>
<th width="30">New<br />Cases</th>
<th width="30">Total<br />Deaths</th>
<th width="30">New<br />Deaths</th>
<th width="30">Total<br />Recovered</th>
<th width="30">Active<br />Cases</th>
<th width="30">Serious,<br />Critical</th>
<th width="30">Tot Cases/<br />1M pop</th>
<th width="30">Deaths/<br />1M pop</th>
<th width="30">Total<br />Tests</th>
<th width="30">Tests/<br />
<nobr>1M pop</nobr>
</th>
<th width="30">Population</th>
<th style="display:none" width="30">Continent</th>
</tr>
</thead>
<tbody>
-- 中略 --
<tr style="">
<td style="font-size:12px;color: grey;text-align:center;vertical-align:middle;">1</td>
<td style="font-weight: bold; font-size:15px; text-align:left;"><a class="mt_a" href="country/us/">USA</a></td>
<td style="font-weight: bold; text-align:right">1,567,112</td>
<td style="font-weight: bold; text-align:right;background-color:#FFEEAA;">+16,818</td>
<td style="font-weight: bold; text-align:right;">93,366 </td>
<td style="font-weight: bold;
text-align:right;background-color:red; color:white">+1,385</td>
<td style="font-weight: bold; text-align:right">362,303</td>
<td style="text-align:right;font-weight:bold;">1,111,443</td>
<td style="font-weight: bold; text-align:right">16,879</td>
<td style="font-weight: bold; text-align:right">4,738</td>
<td style="font-weight: bold; text-align:right">282</td>
<td style="font-weight: bold; text-align:right">12,573,565</td>
<td style="font-weight: bold; text-align:right">38,012</td>
<td style="font-weight: bold; text-align:right"><a href="/world-population/us-population/">330,774,664</a> </td>
<td style="display:none" data-continent="North America">North America</td>
</tr>
-- 後略 --ポイントは以下になります。
1.テーブルのクラス名は”table table-bordered table-hover main_table_countries”
2.<nobr>タグを使って改行を抑制している箇所がある
3.数字はカンマ付きで表現
4.表にアジアやヨーロッパなどの地域ごとの集計や全世界の集計レコードがある
必要なPythonパッケージのインストール
次に、今回使用するPythonパッケージをインストールします。
1.Requests
2.Beautiful Soup4
Python標準ライブラリでURLを開くにはurllibを使いますが、Requestsパッケージを使うとより短いコードで(楽に)開くことができます。
Beautiful Soup4は、HTMLやXMLのパーサー(HTMLやXML文書をプログラムが解釈できるようにオブジェクトに翻訳する機能)とタグの検索機能がセットになったライブラリと考えるとよいでしょう。
両方とも以下のようにpipコマンドにてインストールします。(Windowsでのイメージです)
1.Requestsのインストール
C:>pip install requests
Collecting requests
Downloading requests-2.23.0-py2.py3-none-any.whl (58 kB)
|████████████████████████████████| 58 kB 77 kB/s
Collecting urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1
Downloading urllib3-1.25.8-py2.py3-none-any.whl (125 kB)
|████████████████████████████████| 125 kB 51 kB/s
Collecting certifi>=2017.4.17
Downloading certifi-2020.4.5.1-py2.py3-none-any.whl (157 kB)
|████████████████████████████████| 157 kB 45 kB/s
Collecting idna<3,>=2.5
Downloading idna-2.9-py2.py3-none-any.whl (58 kB)
|████████████████████████████████| 58 kB 41 kB/s
Collecting chardet<4,>=3.0.2
Downloading chardet-3.0.4-py2.py3-none-any.whl (133 kB)
|████████████████████████████████| 133 kB 28 kB/s
Installing collected packages: urllib3, certifi, idna, chardet, requests
Successfully installed certifi-2020.4.5.1 chardet-3.0.4 idna-2.9 requests-2.23.0 urllib3-1.25.8
2.Beautiful Soup4のインストール
>pip install beautifulsoup4
Collecting beautifulsoup4
Downloading beautifulsoup4-4.9.0-py3-none-any.whl (109 kB)
|████████████████████████████████| 109 kB 159 kB/s
Collecting soupsieve>1.2
Downloading soupsieve-2.0-py2.py3-none-any.whl (32 kB)
Installing collected packages: soupsieve, beautifulsoup4
Successfully installed beautifulsoup4-4.9.0 soupsieve-2.0
スクレイピング用のPythonプログラム
WHOサイトのスクレイピング用のPythonプログラムは、以下となります。(2020.4.20更新)
import csv
import requests
from bs4 import BeautifulSoup
# 置換用のディクショナリ
nndict = {"North America":"","Europe":"","Asia":"","South America":"","Oceania":"","Africa":"","World":"","Total:":"","":""}
countrydict = {"USA":"United States of America","China":"People's Republic of China","UK":"United Kingdom","S. Korea":"South Korea","Czechia":"Czech Republic","UAE":"United Arab Emirates","North Macedonia":"Republic of Macedonia","DRC":"Democratic Republic of the Congo","CAR":"Central African Republic"}
columndict = {"CountryOther":"Country","TotalCases":"TCases","NewCases":"NCases","TotalDeaths":"TDeaths","NewDeaths":"NDeaths","TotalRecovered":"TRecovered","ActiveCases":"ACases","SeriousCritical":"Critical","Tot Cases/1M pop":"TC1Mpop","Deaths/1M pop":"D1Mpop","TotalTests":"TTests","Tests/1M pop":"T1Mpop"}
# URLの指定
target_url = "https://www.worldometers.info/coronavirus/#countries"
r = requests.get(target_url)
bsObj = BeautifulSoup(r.text, "html.parser")
# テーブルを指定
table = bsObj.findAll("table", {"class":"table table-bordered table-hover main_table_countries"})[0]
rows = table.findAll("tr")
with open("stat.csv", "w", encoding='utf-8',newline="") as file:
writer = csv.writer(file,delimiter=",")
for row in rows:
csvRow = []
for cell in row.findAll(['th']):
# 項目内のカンマと改行を削除
csvtext = cell.get_text().replace(",","").replace("\n","")
# カラム名を置換
csvRow.append(csvtext if csvtext not in columndict else columndict[csvtext])
# セル位置を示すカウンター
cellcnt = 0
for cell in row.findAll(['td']):
if cellcnt==1:
# セルを取得
csvtext = cell.get_text().replace("\n","")
# 国名を置換
csvRow.append(csvtext if csvtext not in countrydict else countrydict[csvtext])
else:
# セル内のカンマと改行を削除
csvtext = cell.get_text().replace(",","").replace("\n","").replace(" ","").replace("+","").replace("N/A","")
# 数値項目を置換
csvRow.append(csvtext)
# 次のセルへ
cellcnt+=1
if( csvRow[0] not in nndict ):
writer.writerow(csvRow)
print(csvRow)プログラムを簡単に解説します。
1.文字置換用のディクショナリ作成(6~8行目)
表にはアジアやヨーロッパなどの地域ごとの小計や全世界の合計行があるので、それを除外するためのリスト(ディクショナリ)を作成します。
同様に、地図データ(naturalearth)の属性と異なる国名がありますので、置換用のディクショナリも作成しておきます。
2.Requestsを使ってURLを開いて内容を取得(11~12行目)
URLを指定してHTML文書を取得します。
3.Beautiful Soupを使って目的のテーブルデータを取得(14~18行目)
Beautiful Soupのインスタンスを作成し、目的のテーブルからレコード(”tr”タグのデータ)をオブジェクト(rows)として取得します。
4.タブ(カンマ)区切りファイルの作成(20~21行目)
出力用のファイルを開くとともに、CSV(コード上はデリミタにカンマ)出力用のインスタンスを生成します。
5.不要な改行や文字列変換をしてファイルへ格納(22行目以降)
取得したテーブルレコード(row)を1行ずつ取得、更に1カラムごとに取得します。
取得したデータは、ヘッダー部(24~28行目)と、データ部(30~43行目)に分けて必要な置換を行います。
データ部(数値項目)は、更に2項目目(国名)と3項目目以降(数値項目)で編集条件が異なりますので、if文で分けて処理をしています。
レコード出力時には、”Total:”などの不要なレコードの出力抑制(44行目)もしています。
完成したテキストファイル
プログラムを実行すると、以下のようなカンマ区切りファイル(stat.csv)が出力されます。(なお、タブ区切りとするためには先ほどのコードの21行目のデリミタ指定を変更する必要があります。)
#,Country,TCases,NCases,TDeaths,NDeaths,TRecovered,ACases,Critical,TC1Mpop,D1Mpop,TTests,T1Mpop,Population,Continent
1,United States of America,1528179,515,90988,10,346389,1090802,16355,4620,275,11875580,35903,330769370,NorthAmerica
2,Russia,290678,8926,2722,91,70209,217747,2300,1992,19,7147014,48977,145927122,Europe
3,Spain,277719,,27650,,195945,54124,1152,5940,591,3037840,64977,46752654,Europe
4,United Kingdom,243695,,34636,,,,1559,3592,511,2580769,38040,67843268,Europe
最初の1行はヘッダーで、2行目の米国のレコードでは国名が変換(USA→United States of America)されていることがわかります。また、数字のカンマも削除されています。
OpenJUMPを使ってグラフ表示
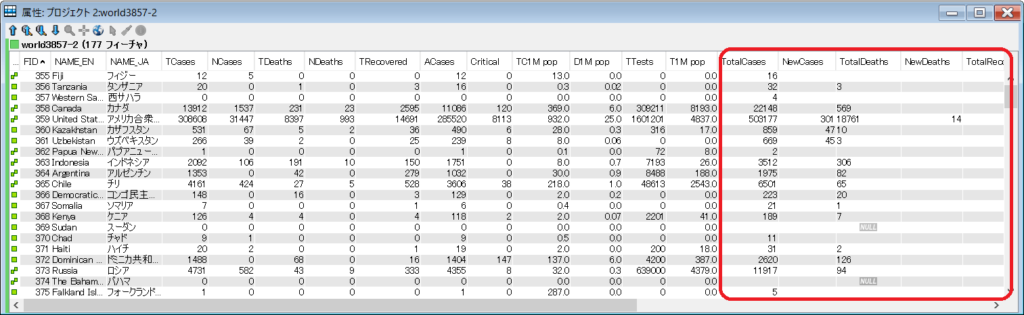
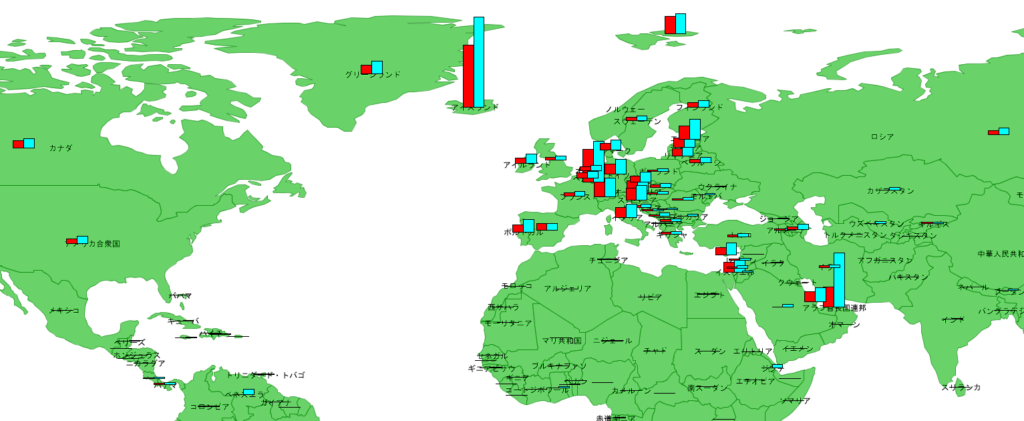
前回の記事を参考にしていただき、先週作成した世界地図(naturalearth)に先ほど抽出したタブ区切りファイルを結合します。結合した結果の属性データが下記になります。(赤枠内が今週分のデータ)
このデータを使って先週分と今週分のグラフを表示します。
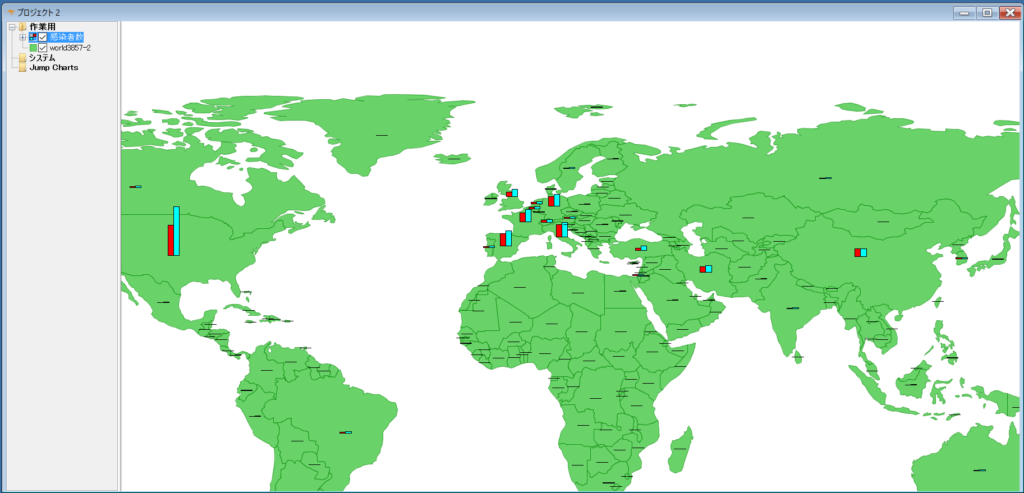
1.感染者数(総数)
感染者数は、アメリカの伸びが際立っています。(棒グラフの赤が先週まで、青が今週までの合計です。)
我が国は、感染者の総数が少ないので差がわかりにくくなっています。
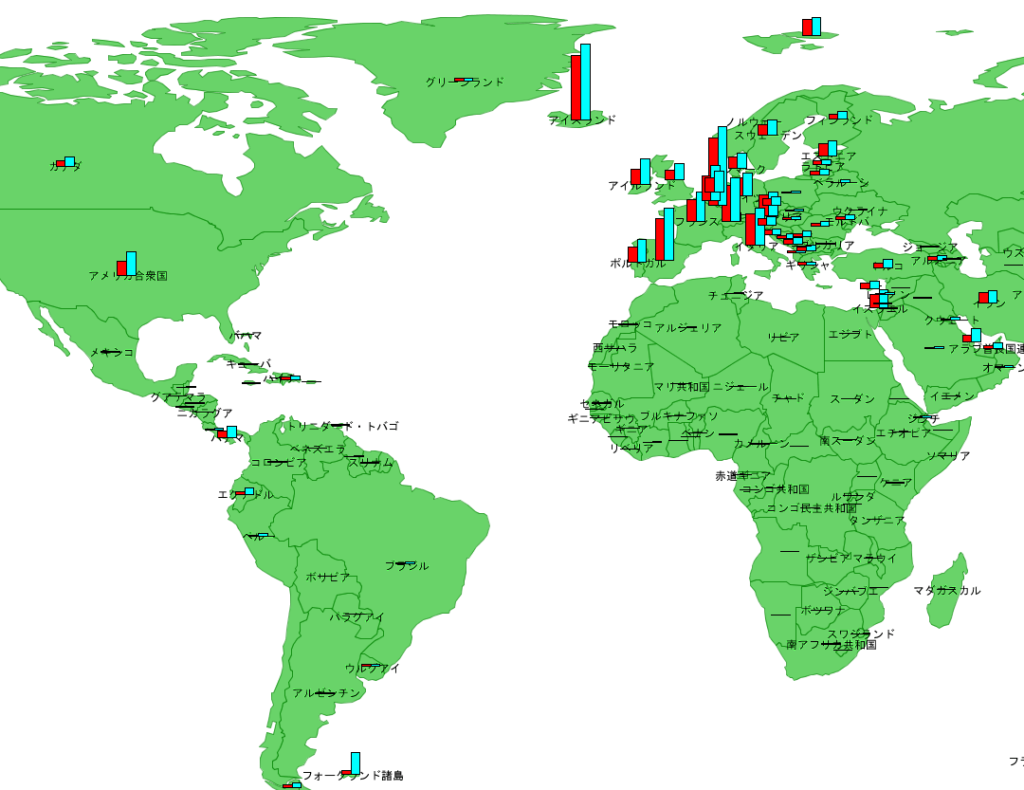
2.100万人あたりの感染者数
次に、100万人あたりの感染者数を確認すると、ヨーロッパ中心部から周辺諸国へ広がっているようにも見えます。
フォークランド諸島のグラフが目立ちますが、2800名余りの人口で感染者数が1名から5名に増えた状況です。
パナマやエクアドルはそれなりの人口がいますので、アメリカから拡散が始まっているのかもしれません。
3.100万人あたりの死亡者数
次に、100万人あたりの死亡者数を確認しましょう。
ヨーロッパは依然としてピークアウトしていないように見え、アメリカは人数は少ないですが増加のペースが急です。
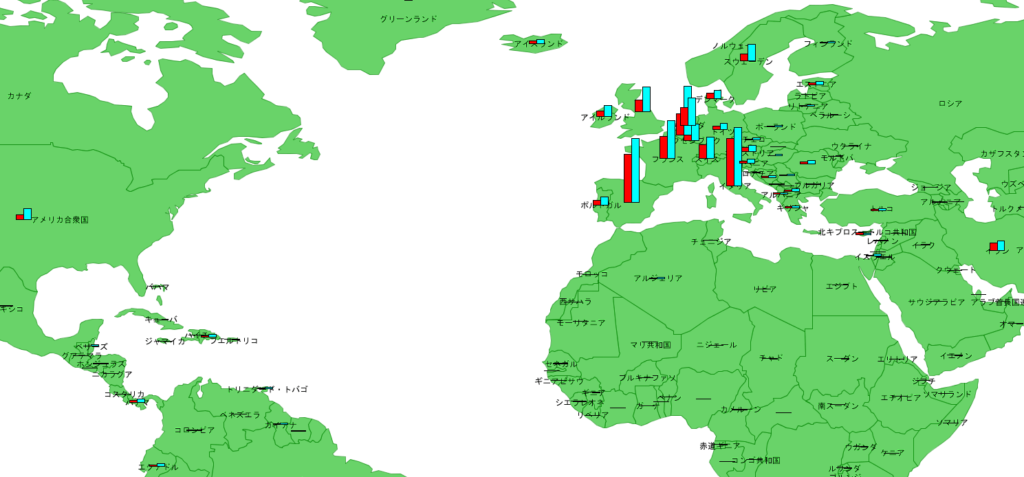
4.100万人あたりの検査数
最後に100万人あたりの検査数を確認しましょう。
UAEが圧倒的に伸びています。また、ロシアやベネズエラといった独裁政権と呼ばれる国々でも検査数が伸びています。
まとめ
今回は、以下を試してみました。
1.PythonとBeautifulSoupによるWebスクレイピング
2.OpenJUMPによるグラフ表示(先週との比較)
報道によると、イタリアの感染発覚は1月29日だったそうです。
日本はそれよりも早く1月15日に初感染者が確認されていますので、2週間日本の方が早く感染者を確認したことになります。
ここからは想像になりますが、初動の対応や習慣、特定のウィルスに対する免疫力の差が感染状況の差を生んだと考えることもできそうです。
いずれにしても、早く感染を終息させ通常の生活に戻らないと経済への打撃が計り知れないと感じる今日この頃です。
私のお客様は、社会の安全上不可欠な業務をしている関係上、出勤せざるを得ない状況なのですが、交代勤務を含め明日以降真剣に人との接触機会を減らす努力をしたいと思います。



