WebGISの構築3−DMデータの変換
今回は、下図赤枠部分のように大阪市DMデータをPythonを使ってGeoJSON形式(テキスト形式です)に変換します。
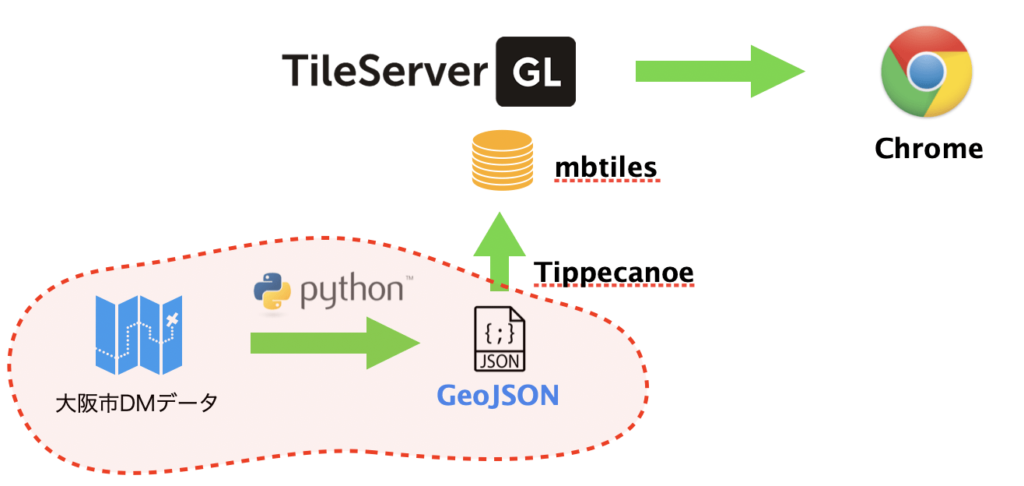
DMファイルのレコード
入力データとなるDMファイルの仕様(テキスト形式で84バイト固定長レコード)は、本連載の第二回にて確認していますので、今回はレコードの仕様を確認します。
インデックスレコード
インデックスレコードとは、DMデータに収容される図郭や図形数雨などの情報を記したレコードです。インデックスレコードは、(a)、(b)、(c)の3種類に別れ、拡張子”.dmi”ファイルに収容されています。
以下にインデックスレコードのフォーマットを示しますが、今回作成するプログラムは図郭レコードと要素レコードを使ってGeoJSON化しますのでインデックスレコードは使用しません。
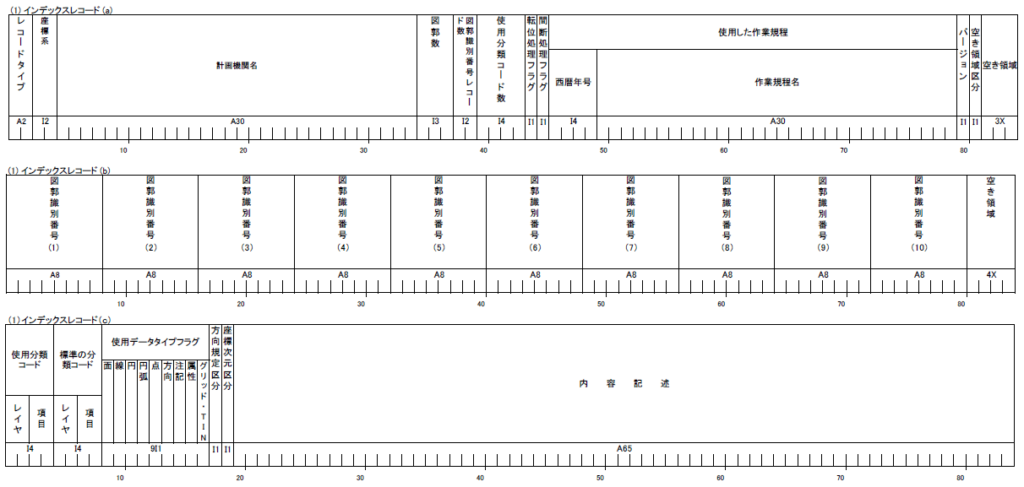
図郭レコード
図郭レコードは、拡張子”.dm”ファイル(以降、DMファイル)に収容されています。レコードは、(a)から(f)までの5種類に分かれており、DMファイルの先頭から記述されています。
今回のプログラムでは、図郭レコードの以下の情報を使用します。
・修正履歴レコードを読み飛ばすための”修正回数”(図郭レコード(a))
・要素の相対座標を測地座標化するための”左下図郭座標”(図郭レコード(b))
・作業機関名や空撮コース情報を読み飛ばすための”レコード数”(図郭レコード(d))
要素レコード
要素レコードは、図郭レコードに続いて記述されており要素(図形、属性)の情報を収容します。要素レコードは、レコードタイプにより”E1”(面)から”E8”(属性)までの8種類の要素を表現できます。
今回のプログラムでは、要素レコードのうち”E1”(線)と”E7”(注記)の2種類をGeoJSON形式に変換します。また、大阪市DMデータには要素種別”E1”(面)が存在しないため、”E1”(線)の始終点が一致するレコードを面化することにします。
要素レコードのレコードタイプにより後続のレコードが決まりますが、”E2”かつ実データ区分が2(二次元)の場合は”二次元レコード”が続き、”E7”の場合は注記レコードが続きます。
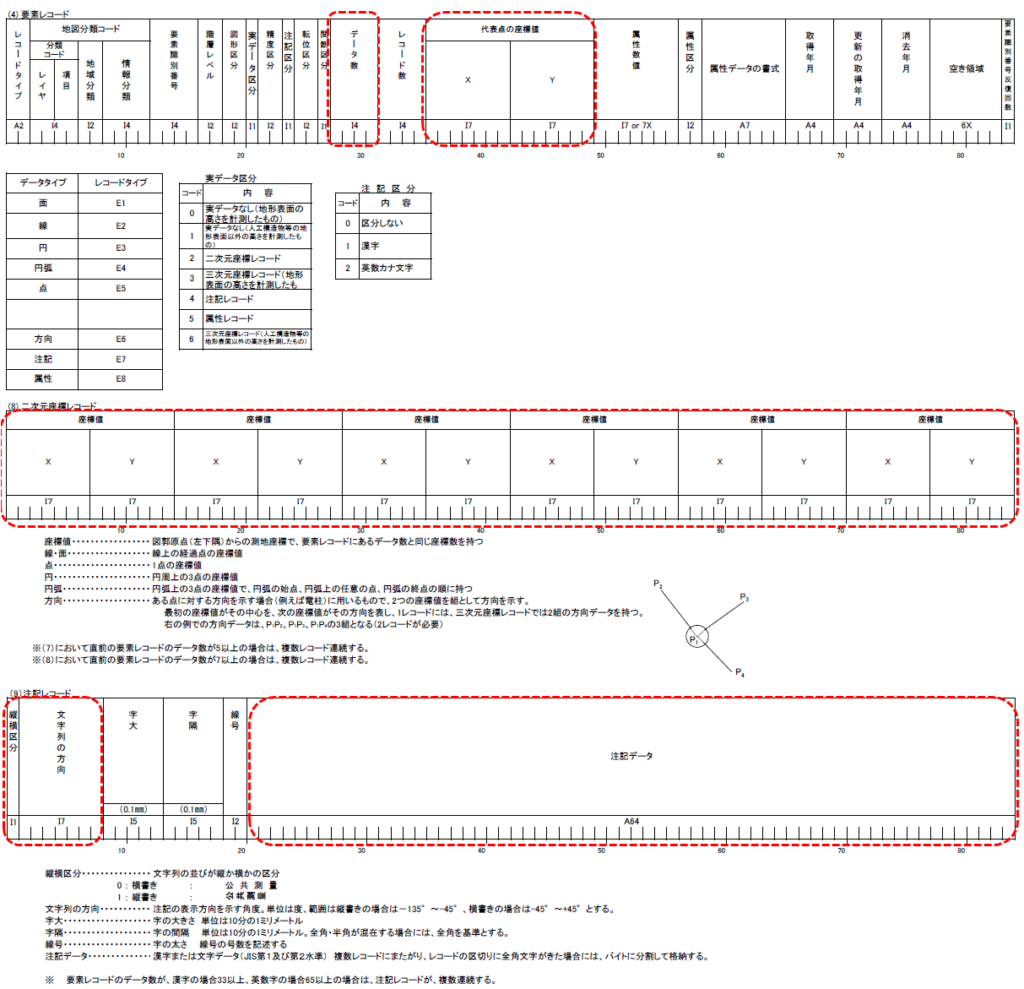
GeoJSONの仕様
GeoJSONは、JSONの仕様を拡張して図形(ジオメトリ)や属性付きの図形(フィーチャー)を収容できるフォーマットと考えるとよいでしょう。以下、GISオープン教材からの引用による説明です。
GeoJSONは、JavaScript Object Notation (JSON) を基とした、GISデータを記述するためのフォーマットです(地理空間データ交換フォーマット)。この形式では、Point, LineString, Polygon, MultiPoint, MultiLineString,MultiPolygon,GeometryCollectionをサポートしています。軽量言語であり、Web GISでの利用例が多く見られます。
「GIS実習オープン教材」GeoJSONの章より引用
https://gis-oer.github.io/gitbook/book/materials/web_gis/GeoJSON/GeoJSON.html
具体的なデータを以下に例示します。
2〜4行目が線要素、5〜7行目が点要素(注記)を表しています。
{"type":"FeatureCollection","features": [
{"type":"Feature",
"geometry":{"type":"LineString","coordinates":[[135.4979582,34.6868559],[135.4979642,34.6866337],[135.4979665,34.686527],[135.4979904,34.6854483],[135.4979914,34.6852815],[135.4980065,34.6841434],[135.4980094,34.6836657],[135.4980227,34.682807],[135.4980223,34.6827652],[135.4980176,34.6822954],[135.497997,34.6816507],[135.4979905,34.6815066]]},
"properties":{"Layer":"1104","Elno":"06OC884-1104-0001"}},
{"type":"Feature",
"geometry":{"type":"Point","coordinates":[135.4517403,34.6628267]},
"properties":{"Layer":"8162","Elno":"06OC971-8162-0167","Text":"夕凪公園","Vnflag":"0","Angle":"0"}},
仕様の説明は、以下がわかりやすいと思います。
https://ja.wikipedia.org/wiki/GeoJSON
変換プログラム
変換プログラムは、以下のGitHubに公開しています。
https://github.com/takamotobiz/dm2geojson
以降、変換プログラムを説明します。
変換プログラムは、以降に示す3つのクラス構成としました。
DMファイル取得クラス
このクラスは、コンストラクタで指定されたディレクトリ配下の拡張子”.dm”ファイルを全て返却します。
イテレータと呼ばれる方法(初期化後に次データを連続して取得する方法)で実装しています。
import glob
import os
# -----------------------------------------
# DMファイルリスト管理クラス
# 2020.05.23 K.Takamoto(takamoto.biz)
# -----------------------------------------
class DMFiles:
#============================================================
# コンストラクタ
# out: self._MAPPath、self._MAPList
#============================================================
def __init__( self ,inPath ):
# パスを保存
self._MAPPath = inPath
# ディレクトリの存在確認しdmファイルのリストを作成
if os.path.exists(self._MAPPath):
self._MAPList = glob.glob( self._MAPPath + "/*.dm")
else:
self._MAPList = None
#============================================================
# Function : イテレータ開始処理:イテレータの初期化
#============================================================
def __iter__(self):
# イテレータ用カウンタ初期化
self._i=0
# それ以外の処理はコンストラクタで済んでいる。(self._MAPListへのファイルリスト作成)
return self
#============================================================
# Function : イテレータ取得処理:指定ファイルの形状情報を順次読みだす。
# out: _MAPListのメンバー(DATファイルのフルパス)
#============================================================
def __next__(self):
# データなしの場合は終了
if self._MAPList == None:
raise StopIteration()
# データありの場合は次データ取得
if self._i >= len(self._MAPList):
raise StopIteration()
value = self._MAPList[self._i]
self._i+=1
return value
処理の概要は、以下となります。
[table id=16 column_widths=”15%|20%|65%” /]
DMデータ取得クラス
このクラスは、コンストラクタで指定された”.dm”ファイルの図郭レコードと要素レコードを読み込み配列として返却します。
このクラスもイテレータ形式で実装しています。
import struct
import numpy
# -----------------------------------------
# DM DATファイル読み込みクラス
# 2020.05.23 K.Takamoto(takamoto.biz)
# -----------------------------------------
class DM:
#============================================================
# コンストラクタ
# out: self._DATFile
#============================================================
def __init__(self ,inDMFile ):
# 入力ファイルをクラス変数に保存
self._DMFile = inDMFile
# 図形情報出力用ディクショナリ配列の宣言(0始まり)
self._elementDict = {}
#============================================================
# Function : イテレータ開始処理:指定ファイルの形状情報をすべて読みだす。
# in : None(コンストラクタの引数 inATRFile)
# out : 図形情報の配列(self.elementDict)
#============================================================
def __iter__(self):
# DATファイルの読み込み
with open(self._DMFile ,mode='rb') as dmfd:
# 全レコードの読み込み(バイナリでも行として取得できる模様)
# DMファイルの1レコードは87バイト(CR+LFの2バイトを含む)
# DMファイルの最後のEOF(0x1A)の明示的な取得は不要
self._reclist = dmfd.readlines()
# レコードカウンタ初期化
dictSeqno = recno = 0
while recno < len(self._reclist)-1:
# レコードの取得
record = self._reclist[recno]
# レコードタイプの取得
rectype = str(record[0:2].decode('cp932'))
# レコード判定
if rectype[0]=='M':
# 図郭レコード(a) 図郭ごとに1レコード群のみ
# 図郭識別番号
self.unitcode = str(record[2:10].decode('cp932')).rstrip()
# 修正回数取得
editcnt = int(record[65:67].decode('cp932'))
recno+=1
# 図郭レコード(b)の取得(単位はメートル)
record = self._reclist[recno]
self.ldx = float(record[0:7].decode('cp932'))
self.ldy = float(record[7:14].decode('cp932'))
# 図郭レコード(d)までシーク
recno += 2
cnt = 0
while cnt < editcnt+1:
# 図郭レコード(d)の取得(捨て)
record = self._reclist[recno]
reccnt = int(record[9:10].decode('cp932'))
recno += reccnt+2
cnt += 1
elif rectype[0]=='E':
# 要素レコード("E1"~"E8")
# 分類コード
layercode = str(record[2:6].decode('cp932'))
# 要素識別番号
elementno = int(record[12:16].decode('cp932'))
# レコード数
recordcnt = int(record[31:35].decode('cp932'))
# 実データ区分(0,1:データなし、2:二次元、4:注記)
datakind = str(record[20:21].decode('cp932'))
# データ数(座標点数、文字数)
datacnt = int(record[27:31].decode('cp932'))
if rectype=='E1' or rectype=='E2':
# 線(E2)と面(E1)
# 実データレコード取得Loop
pointcnt = cnt = 0
xy = []
# 座標情報の取得
while pointcnt < datacnt:
if ( pointcnt % 6 )==0:
# 二次元座標レコード(8)の取得
recno += 1
record = self._reclist[recno]
start = ( pointcnt * 14 ) % 84
# 座標をミリメートルからメートルに変換
xy.append( [ self.ldy + float(record[start+7:start+14].decode('cp932'))/1000, \
self.ldx + float(record[start:start+7].decode('cp932'))/1000 ] )
#print(float(record[start:start+7].decode('cp932')) ,float(record[start+7:start+14].decode('cp932')))
pointcnt += 1
# 始終点が一致していれば面化する
if xy[0]==xy[len(xy)-1]:
rectype = 'E1'
# ディクショナリへのデータ設定
self._elementDict[dictSeqno] = {"FIGTYPE":rectype,"LAYER":layercode, \
"ELNO":self.unitcode + '-' + layercode + '-' + str(elementno).zfill(4),\
"XYList":xy}
#print(self._elementDict[dictSeqno])
# ディクショナリカウンタの加算
dictSeqno += 1
# レコードカウンタの加算
recno += 1
elif rectype=='E7':
# 注記(E7)
# 代表点座標(ミリメートルからメートルに変換)
pointxy = [ self.ldy + float(record[42:49].decode('cp932'))/1000 , \
self.ldx + float(record[35:42].decode('cp932'))/1000 ]
# 二次元座標レコード(8)の取得
record = self._reclist[recno+1]
# 縦横フラグ(0:横書き、1:縦書き)
vnflag = str(record[0:1].decode('cp932'))
# 角度(横書き:-45~45、縦書き:-135~-45)
angle = int(record[1:8].decode('cp932'))
# 注記文字:今回は1レコード目まで。2レコード目以降は捨てる
text = str(record[20:84].decode('cp932')).rstrip()
#print(str(elementno) +':' + text)
# ディクショナリへのデータ設定
self._elementDict[dictSeqno] = {"FIGTYPE":rectype,"LAYER":layercode, \
"ELNO":self.unitcode + '-' + layercode + '-' + str(elementno).zfill(4),\
"XYList":pointxy ,"ANGLE":angle ,"VNFLAG":vnflag ,"TEXT":text}
#print(self._elementDict[dictSeqno])
# ディクショナリカウンタの加算
dictSeqno += 1
# レコード数分シーク
recno += recordcnt+1
else:
# レコード数分シーク
recno += recordcnt+1
elif rectype[0]=='H':
# グループヘッダレコード
recno += 1
elif rectype[0]=='G' or rectype[0]=='T':
# グリッドヘッダ、TINレコード
# レコード数
recordcnt = int(record[31:35].decode('cp932'))
recno += recordcnt+1
# イテレータ用カウンタ初期化
self._i=0
return self
#============================================================
# Function : イテレータ取得処理:指定ファイルの形状情報を順次読みだす。
# in : 図形情報の配列(self.elementDict)
# out : 図形情報(self.elementDictのメンバ)
#============================================================
def __next__(self):
if self._i >= len(self._elementDict):
raise StopIteration()
value = self._elementDict[self._i]
self._i+=1
return value
処理の概要は、以下となります。
[table id=17 column_widths=”15%|20%|65%” /]
GeoJSON出力クラス
このクラスは、コンストラクタで指定されたファイルにセットされた座標や属性を出力します。
なお、110行目以降がこれまで作成した各クラスを呼び出すメイン処理となります。
# -----------------------------------------
# GeoJSON出力用クラス 2020.5.24 K.Takamoto(takamoto.biz)
# -----------------------------------------
import numpy as np
# 座標系変換のために追加
from pyproj import Proj ,Transformer ,itransform
class GeoJSONWriter:
# コンストラクタ
def __init__( self ,inOutFile ):
# 出力ファイルのオープン(とりあえず失敗・例外を考慮しない)
self._jsonfd = open(inOutFile ,'w' ,encoding='utf-8')
# ジオメトリとプロパティをクリア
self.Geometry = None
self.Properties = None
self.Tippecanoe = None
# 世界測地系測地平面直角6系からWGS84への変換器作成
self._srcproj = Proj(init='epsg:2448', preserve_units=False)
self._dstproj = Proj(init='epsg:4326', preserve_units=False)
self._transtky2wgs = Transformer.from_proj(self._srcproj,self._dstproj)
# デストラクタ
def __del__(self):
# フッターを書き込み
self._jsonfd.write( "\n" + "]}")
# ファイルのクローズ
self._jsonfd.close()
# ジオメトリの設定
def setGeometry(self ,inFigtype ,inXyList):
# 座標の変換
if inFigtype==1:
# FIGTYPE=1 : 折れ線
self.Geometry = "\t" + "{" + "\"" + "type"+ "\"" + ":" +"\"" + "Feature" +"\"" + "," + "\n"
self.Geometry+= "\t" + "\"" + "geometry"+ "\"" + ":{"
self.Geometry+= "\"" + "type"+ "\"" + ":" + "\"" + "LineString" + "\"" + ","
self.Geometry+= "\"" + "coordinates"+ "\"" + ":" +"["
for Xy in inXyList:
# 座標変換
Xy = self._transtky2wgs.transform(Xy[0] ,Xy[1])
self.Geometry+= "[" + str(str(round(Xy[0],7))+","+str(round(Xy[1],7))) + "],"
# 最後の1文字をカンマから]に置き換え(イテレータのhasNextがないため)
self.Geometry = self.Geometry[:-1]
self.Geometry+="]"
elif inFigtype==2:
# FIGTYPE=2 : ポリゴン
# 座標を逆転させて始終点を一致
XyList = np.flipud(inXyList)
XyList = np.append(XyList ,XyList[[0]] ,axis=0)
self.Geometry = "\t" + "{" + "\"" + "type"+ "\"" + ":" +"\"" + "Feature" +"\"" + "," + "\n"
self.Geometry+= "\t" + "\"" + "geometry"+ "\"" + ":{"
self.Geometry+= "\"" + "type"+ "\"" + ":" + "\"" + "Polygon" + "\"" + ","
self.Geometry+= "\"" + "coordinates"+ "\"" + ":" +"[["
for Xy in XyList:
# 座標変換
Xy = self._transtky2wgs.transform(Xy[0] ,Xy[1])
self.Geometry+= "[" + str(str(round(Xy[0],7))+","+str(round(Xy[1],7))) + "],"
# 最後の1文字をカンマから]に置き換え(イテレータのhasNextがないため)
self.Geometry = self.Geometry[:-1]
self.Geometry+="]]"
elif inFigtype==4:
# FIGTYPE=4 : 文字
self.Geometry = "\t" + "{" + "\"" + "type"+ "\"" + ":" +"\"" + "Feature" +"\"" + "," + "\n"
self.Geometry+= "\t" + "\"" + "geometry"+ "\"" + ":{"
self.Geometry+= "\"" + "type"+ "\"" + ":" + "\"" + "Point" + "\"" + ","
self.Geometry+= "\"" + "coordinates"+ "\"" + ":"
# 座標変換
Xy = self._transtky2wgs.transform(inXyList[0] ,inXyList[1])
self.Geometry+= "[" + str(str(round(Xy[0],7))+","+str(round(Xy[1],7))) + "]"
elif inFigtype==6:
# FIGTYPE=6 : 記号
pass
# プロパティの設定
def setPropertie(self ,inName ,inValue):
# 2つ目以降か?
if self.Properties==None:
# 1つ目
self.Properties = "\t" + "\"" + "properties"+ "\"" + ":{"
else:
# 2つ目以降
self.Properties+= ","
if type(inValue) is list:
# 文字列リスト
self.Properties+= "\"" + inName + "\""+":" + "\"" + "".join(inValue) + "\""
else:
# 文字列項目
self.Properties+= "\"" + inName + "\""+":" + "\"" + str(inValue) + "\""
# プロパティの設定
def setTippecanoe(self ,inValue):
self.Tippecanoe = "\t" + "\"" + "tippecanoe" + "\"" + ":{" + "\"" + "layer" + "\"" + ":" + "\"" + str(inValue) + "\""
# ファイルの書き込み
def Write(self):
if self._jsonfd.tell()==0 :
# 最初はヘッダーを書き込み
self._jsonfd.write("{" + "\"" + "type" + "\"" + ":" + "\"" + "FeatureCollection" + "\"" + "," + "\"" + "features" + "\"" + ": [" + "\n")
else:
# 最初の書き込み以外
self._jsonfd.write(",\n")
self._jsonfd.write(self.Geometry + "}," + "\n")
self._jsonfd.write(self.Tippecanoe + "}," + "\n")
self._jsonfd.write(self.Properties + "}"+"}")
# ジオメトリとプロパティをクリア
self.Geometry = None
self.Properties = None
self.Tippecanoe = None
if __name__ == '__main__':
from DMFiles import DMFiles
from DM import DM
#
gjWriter = GeoJSONWriter( r"/Users/takamotokeiji/data/dm_osaka/osaka.json" )
# DMファイルインスタンスの生成
dmfiles = DMFiles( r"/Users/takamotokeiji/data/dm_osaka/DM" )
# 存在ファイル分Loop
for dmfile in dmfiles:
print('File:[' + dmfile + ']')
# DATファイル内の全要素を取得(配列)
dats = DM(dmfile)
for dat in dats:
if dat["FIGTYPE"]=='E2':
# 折れ線
# 1.ジオメトリの出力
gjWriter.setGeometry( 1, dat["XYList"] )
# 2.Tippecanoeタグ出力
gjWriter.setTippecanoe(dat["LAYER"])
# 3.プロパティ出力
gjWriter.setPropertie("Layer" ,dat["LAYER"])
gjWriter.setPropertie("Elno" ,dat["ELNO"])
# ファイル出力
gjWriter.Write()
elif dat["FIGTYPE"]=='E1':
# ポリゴン
# 1.ジオメトリの出力
gjWriter.setGeometry( 2, dat["XYList"] )
# 2.Tippecanoeタグ出力
gjWriter.setTippecanoe(dat["LAYER"])
# 3.プロパティ出力
gjWriter.setPropertie("Layer" ,dat["LAYER"])
gjWriter.setPropertie("Elno" ,dat["ELNO"])
# ファイル出力
gjWriter.Write()
elif dat["FIGTYPE"]=='E7':
# 文字
# 1.ジオメトリの出力
gjWriter.setGeometry( 4, dat["XYList"] )
# 2.Tippecanoeタグ出力
gjWriter.setTippecanoe(dat["LAYER"])
# 3.プロパティ出力
gjWriter.setPropertie("Layer" ,dat["LAYER"])
gjWriter.setPropertie("Elno" ,dat["ELNO"])
gjWriter.setPropertie("Text" ,dat["TEXT"])
gjWriter.setPropertie("Vnflag" ,dat["VNFLAG"])
gjWriter.setPropertie("Angle" ,dat["ANGLE"])
# ファイル出力
gjWriter.Write()
# DATオブジェクトの消去
dats = None
処理の概要は、以下となります。
[table id=18 column_widths=”15%|20%|65%” /]
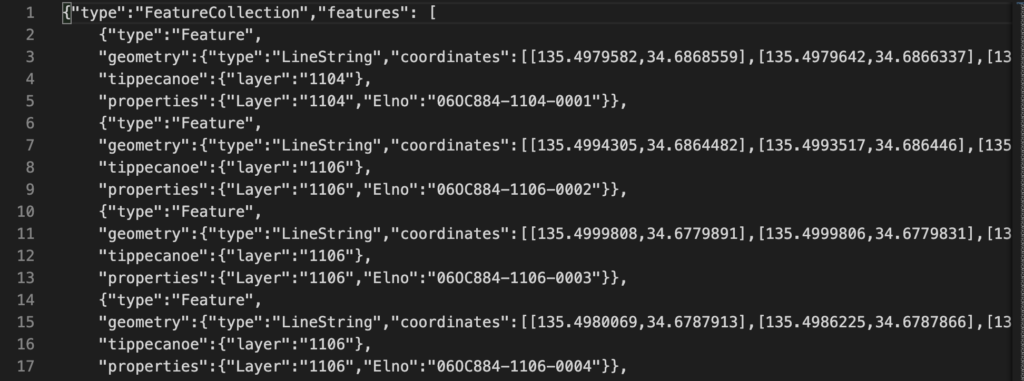
完成したGeoJSONファイル
前述の処理を実行し完成したGeoJSONファイル(先頭部分)を以下に示します。
行数にして約600万行、ファイルサイズ447MBとなりました。
完成したGeoJSONデータを地図に表示してみましょう。
OpenJUMPにて地図に表示し、面レイヤを塗り潰し、注記レイヤの文字列をラベルとして表示しています。
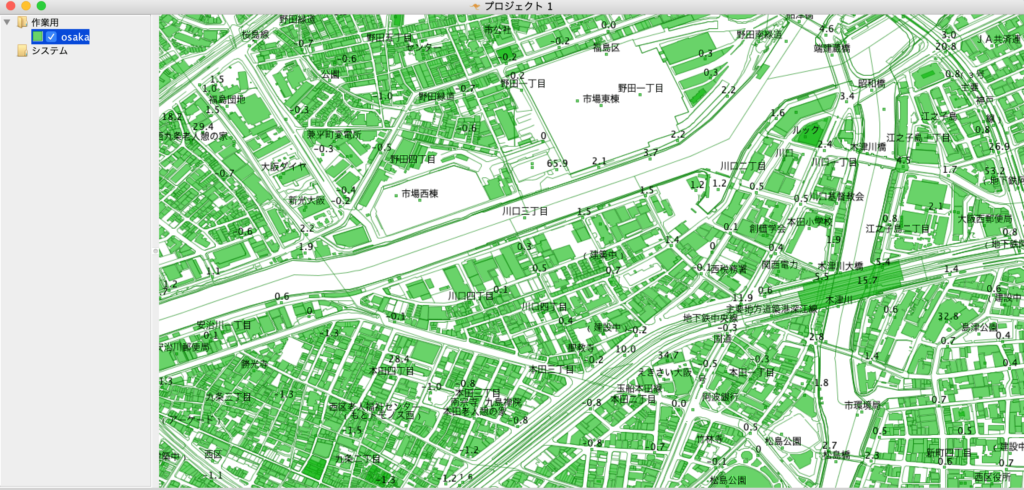
まとめ
今回は、DMデータの各レコードの仕様とPythonによるGeoJSON形式への変換プログラムを作成しました。
次回は、GeoJSONファイルを端末へ配信するための”mbtiles形式”への変換を行います。
以下に今回作成したmbtilesを配信するデモサイトがあります。
[blogcard url=”https://labo.takamoto.biz/osakadm.html”]
マウス右ボタンドラッグで3D表示できます。
なお、IE(インターネットエクスプローラ)では表示できませんので、Chromeなど他のブラウザをご利用ください。


