Pythonでログファイル集計
今回は、Pythonでログファイルの集計ツールを作成しましたのでレポートします。
作成のきっかけ
ここのところ、年度末ということで現場に行くことが増えていましたが、作業の待ち時間に当社の若者がログの分析で困っているようなので声をかけると、“エクセルに数十万件のログファイルを読み込ませると重くて動かなくなる”とのことでした。
話を聞いていくと、担当している動態管理GISにて車両が一斉に動くと動作が重くなってユーザーからクレームが出ているため、ログから移動情報を10分単位に集計しピークの電文数や時刻などを分析したいとのことでした。
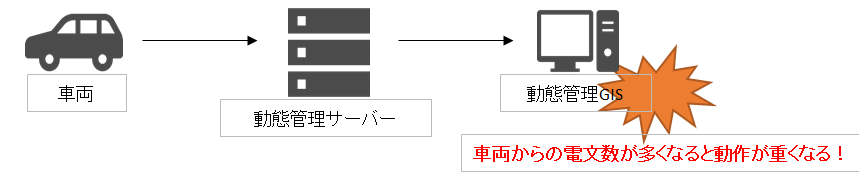
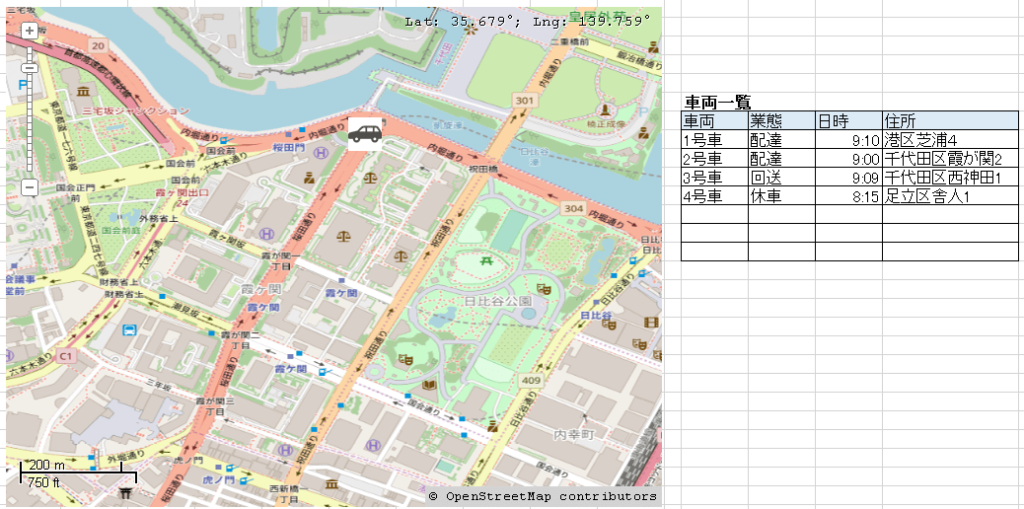
動態管理GISは、以下のように地図と一覧に車両を表示し、車両の状況や管理センターからの指示を行うようなシステムです。車両が頻繁に移動するピーク時刻になると、地図上の車両か一覧表示のどちらかがネックとなってシステムの動作が重くなるとのことです。
ここは一肌脱いで若者を助けるために集計プログラムを作成することにしました。
ログファイルの概要
問題のログファイルは、車両が移動すると1行生成され緯度経度や従事中の作業種別などから構成されています。フォーマットは、以下のようなイメージです。
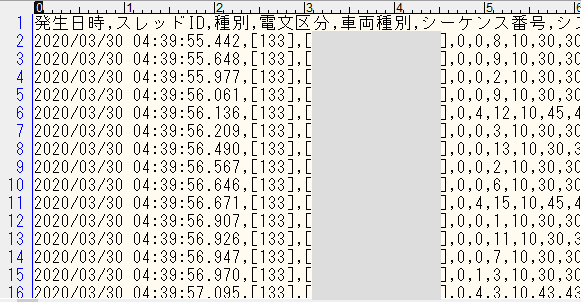
- 1レコード約40項目、先頭は日時分秒(ミリ秒)、先頭行はヘッダー
- GISの移動データ受信時に出力されるログで、log4net(ログ出力ライブラリ)にて出力
- 1ファイルあたり約10万件、サイズは20MB、2時間分
- ログファイルのタイムスタンプは次ファイル切り替え直前の最終記録時刻
- 丸一日分分析するためには、上記ファイルを10フィル以上読み込む必要がある
集計プログラムの概要
今回は、ログファイルのレコード数を1分単位や10分単位で集計し、以下のようなCSVファイルを作成するPythonプログラムを作成しようと思います。
2020/03/30 01:12,1008
2020/03/30 01:13,920
2020/03/30 01:14,1046
- 1カラム目が集計日時、2カラム目が件数
- ファイルには移動情報が時系列に出力されているためCSVファイルを時系列に処理できれば、ファイルを順次読み込んで集計処理すればよい
作成したプログラム
2時間ほどかけて以下のプログラムを作成しました。
import os
import glob
import csv
import datetime
# カーロケログフォルダ
CARLOC_DIR = "C:\\work\\遅延ログ"
# 集計結果ファイル名
OUT_FILE = ".\\carsum.csv"
# ファイルリストを取得
carloglist = sorted( glob.glob( CARLOC_DIR + "\\" + "Telegram.log*"),key=lambda f: os.stat(f).st_mtime,reverse=False)
# 出力ファイルオープン
outfd = open( OUT_FILE ,"w")
# ファイルLoop
mincount = 1
for carlogfile in carloglist:
with open(carlogfile) as carlog:
# レコードLoop
carlog = csv.reader(carlog)
lastymdhm = ymdhm = None
for car in carlog:
# ヘッダーを捨てる
if( car[0]=="発生日時" ):
continue
# 日時分の取得
ymdhm = car[0][:15]
if ( lastymdhm == None ):
# 最初の1回目
lastymdhm = ymdhm
elif ( lastymdhm == ymdhm ):
# 同じ分の場合
mincount+=1
else:
# 分が変わった場合
outfd.write(lastymdhm + "," + str(mincount) + "\n")
# 値初期化
lastymdhm = ymdhm
mincount = 1
# 出力ファイルを閉じる
outfd.close()ログファイルをタイムスタンプ順にオープンしてレコードを順次読み込み、レコードの先頭15文字(日時分)ごとにレコード数を集計しCSVファイルへ出力する処理としています。
コード上のポイント
コード上のポイントは、以下の通りです。
1.ファイルをタイムスタンプ順に取得(12行目)
carloglist = sorted( glob.glob( CARLOC_DIR + “\\” + “Telegram.log*”),key=lambda f: os.stat(f).st_mtime,reverse=False)
sorted関数の引数2(ソートキー)にラムダ式を使ってファイルのタイムスタンプを設定し、引数3でソート順を指定します。
carloglistには、タイムスタンプジョンのログファイルのフルパスがリストで取得されます。
2.CSVファイルの2次元配列化(21行目)
carlog = csv.reader(carlog)
CSVライブラリ(3行目でインポート)を使って読み込んだCSVファイルを2次元配列化します。
3.配列化されたCSVレコードを配列変数に順次取得(23行目)
for car in carlog:
配列化されたCSVレコードの1行を変数carに取得します。変数carはCSV項目ごとの配列となります。
4.ログファイルの日時分の取得
ymdhm = car[0][:15]
ログファイルのレコードの1カラム目の先頭から15文字(分まで)を取得します。
まとめ
Pythonは、ネット上にTipsが数多くありますので、”こんな処理をしたい”ということが明確であれば、あまり苦労なくコードが書けると思います。
また、今回のような短いコード(実質15行程度)であっても統合開発環境(VSCode)を使うと作業効率(生産性)が大きく向上しますので、エディタ派の方は参考にしてください。
[blogcard url=”https://azure.microsoft.com/ja-jp/products/visual-studio-code/”]
作業依頼者の若者からは、社内チャット(MS Teams)で“ありがとうございました!”と、感謝ともフォローとも取れない返信がありました。
早くボトルネックを特定してお客様のクレームを取り除いてほしいなと思っています。
以下の記事では、GPSから取得したNMEA0183電文をPythonを使ってGeoJSON形式に変換し、QGISに表示するまでを解説していますので、よかったら読んでみてください。
[blogcard url=”https://takamoto.biz/other/gps2/”]

